Atcoder日記ー2022年2月編ー
Atcoderを今年の目標に掲げたため、その取り組みをブログとしても残していこうと思います。
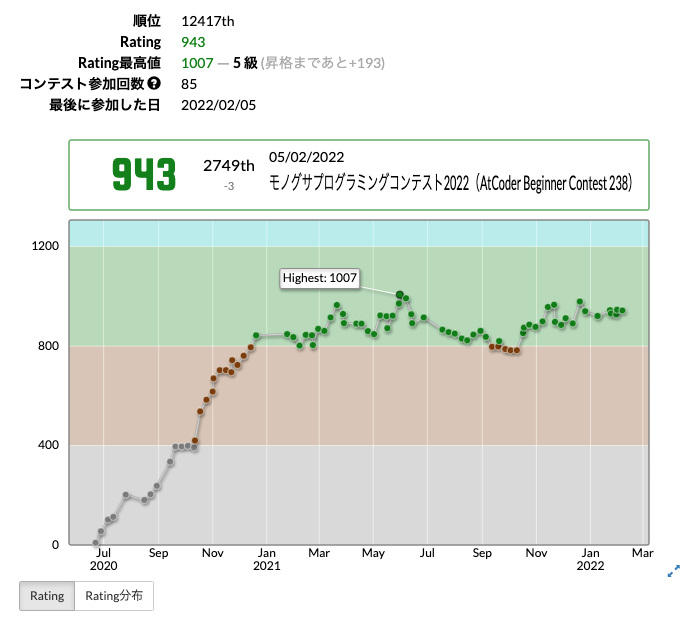
目標感としては、2022年内に青色になること(少なくとも水色にはなっていたい)なので、それまでの勉強過程や毎日何に取り組んだか、を記録していく予定です。自分の成績は、今のところこんな感じです。
プロフィールページは↓
ブログに書くことで、何をやってきたのかを把握し、達成感を味わって継続しやすくすることを目的としています。たまにはアルゴリズムの解説記事や問題の解説記事を書いたり、自分のライブラリをまとめたりできたらなと思っています。
まだまだ基本的なアルゴリズムの理解が足りていない部分(赤黒木とか、、、)も多いですし、実装力が足りていない部分も多いです。。
Atcoderのコンテストに出て問題が解けなかった時、「問題を解く発想ができなかった時(もしくは該当のアルゴリズムを知らなかった時)」と「発想はできたけどうまくコードに落とせない時」があると思っていて、自分は両者どちらも訓練が必要だと認識しています。なので分からなかった問題は解説を読んで、必ず自分でコードを書くところまでやるということを意識して取り組んでいこうと思います。
コードはGithubにあげていく予定↓
github.com
ブログ初日(2月12日)
前回のコンテスト(ABC238)に出た問題の復習(〜E問題まで)。
ABCコンテストが延期になったため、コンテストの参加は無し。
ブログ2日目(2月13日)
典型問題6↑これは前にコンテストで見た問題と似ていたため、自力で解けました(どの問題だったかは忘れてしまいました…)
典型問題8
↑こちらも基本的な動的計画法(DP)で自力で解くことができました
ARC135に参加
A問題しか解けませんでした…
ブログ3日目(2月14日)
ARC135の復習(〜B問題の途中まで)ブログ4日目(2月15日)
この日は復習の時間が取れず…ブログ5日目(2月16日)
ARC135の復習(〜B問題の途中まで)解説と睨めっこ中
ブログ6日目(2月17日)
この日は復習の時間が取れず…ブログ7日目(2月18日)
この日は復習の時間が取れず…ブログ8日目(2月19日)
ARC135の復習(〜C問題の途中まで)ブログ9日目(2月19日)
ARC135の復習(〜C問題の途中まで)ABC239参加
D問題までは自力で解けたが、E問題のKの値域を勘違いしていて解放が思いつかなかった…
オイラーツアーまでは発想できていたので、もう少しといった印象
ブログ10日目(2月20日)
ARC135の復習(〜C問題まで)※実装はまだ
ABC240参加
D問題までは解けたが、E・F問題が解けなかった…
ブログ11,12,13,14,15日目(2月21,22,23,24,25日)
復習の時間が取れず…ブログ16日目(2月26日)
ABC241参加C問題までは解けたが、D問題以降は解けず、、、
最近復習が間に合わなくなってきた、、
2021年の振り返りと2022年の抱負
目次
2021年振り返り
NAIST博士前期課程(修士課程)修了

博士後期進学を考えていた自分にとって、非常に大きなイベントでした。文系出身で、初めて情報系の分野を専門的に学び、その上研究もするという少しハードな生活を行なっていましたが、研究の進捗が著しくありませんでした。修士ではよくあることですが、外部発表1件以上が暗黙の卒業要件となっており(国内の学会や研究会で良い)、それを達成するのが精一杯で、研究室の進学要件(国際会議に投稿)を間に合わせることができず、修士をとって修了するのか、留年して進学を目指すのか、選択を迫られることになりました。経済的にも奨学金が借りられなくなり、アルバイトをフルタイムでやりつつ研究も行うのは時間的に難しいため、今回は進学せずに修了しようと決断しました。
また機会があれば、社会人博士や定年後の博士を狙っても良いのではと思っています。いくら奨学金があると言えど、経済面でかなり圧迫されることになったので(同じ20代の社会人出身者は口を揃えてこれを言っていました。特に初年度の税金や保険料がバカにならないので…)、今度挑戦する時は、お金に余裕ができたタイミングでやろうと思います!(お金は大切!笑)
研究がうまく進まなかった原因としては、自分の時間をあまり研究に割けなかったこと(授業を多くとってしまったり、完璧にやろうとして時間を浪費してしまったりしたこと)や、研究の課題をうまく細分化して自分の解くべき問題に落とし込むのが遅れてしまったことがあります。ただ、失敗を経験しただけに、時間の使い方や課題の細分化に気をつけるようになった点はよかったです。
進学して一番よかった点は、自分の研究分野(機械翻訳)に興味のある人たちが(所属研究室内外含めて)たくさんいて、そういった方達と仲良くなれたことが一番よかったのではないかと思っています!
最終的には国内学会(言語処理学会)に投稿&発表し、修士論文も書き上げて修了することができました!学位としては、工学修士です!!(就活は卒業後にしましたが、無事京都のベンチャーで働いています!)

2022年の抱負
今年は機械学習やデータサイエンス、競プロに力を入れたいと思っているので、Kaggle、Atcoderをメインで取り組んでいこうと思います!その他の目標も含めて、まとめると、
です!それぞれ進捗がでたり、解説記事が書けるものがあれば書いていきたいと思います。よろしくお願いします!
三角関数の微分

現在のDeepLearningのアルゴリズムにも採用されているものもあります.覚えていない人は頑張って覚えましょう.
エンジニアの方は,思い出すために使っていただけたら嬉しいです.
目次
三角関数の基本極限
は
,
を用いて表現できるため,
,
の導関数を求めることが基本になります.直接これらを導くことはできないため,先ずは次の式を値求めることから始めます.
ここで,原点Oを基準とする単位円(半径1の円)上の点A,Bを次のように取り,単位円に内接する直角三角形と外接する直角三角形を考えます.角BPOと角QAOはそれぞれ直角です.

扇型OABに着目します.扇型OABの面積は次のように表せます(面積をSとする).
※ θは単位:ラジアンを示しています.360℃=2π (ラジアン)です.
面積に着目すると,△OBPの面積は下記のように表せます(△OBP=Tとする).
△OAQも同様に(△OAQ=Uとする),
S,T,Uの大小関係は図より,
T(△OBP) ≦ S(扇型OAB) ≦ U(△OAQ) となる.よって,
θを0に近づけた時の極限を考えてみる.
これらを利用して,はさみうちの原理より,
分母分子を入れ替えても同様に,
となります!1つ目の証明が完了しました!2つ目の式は式変形と今回得た式を利用して証明していきます.
目標だった下記の式を求めることができました!
ようやく三角関数の微分に本格的に入っていくことができます.
三角関数の微分
前述の通り,まず ,
の導関数を求めていきます.
この式を変形するために,加法定理を使用します.加法定理は次のような定理です.
これを使って,
求めたい式の値が求まりました!まとめると,
となります.この式に合成関数の微分を適用すると, の導関数も求めることができます.
(合成関数の微分を忘れた方はこちらを参照ください)
まとめると,
です.続けて の導関数も見ていきましょう.
意外と簡潔に終われましたね.導出完了です.お疲れ様でした.
Pytorch import 時にエラーが出た時の対処法

Pytorchを使おうとしたら,意味が分からないエラーに遭遇したので,
備忘録として対処法を綴っていきます.
対象のエラーは以下の通りです.
import torch Traceback (most recent call last): File “”, line 1, in File “/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/__init__.py”, line 79, in from torch._C import * ImportError: dlopen(/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/_C.cpython-37m-darwin.so, 9): Library not loaded: /usr/local/opt/libomp/lib/libomp.dylib Referenced from: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/torch/lib/libshm.dylib Reason: image not found
DLLの処理の時にリンク先が無いと言うエラーの模様.
確かに libomp.dylib と言うファイルがないことが発覚.
使用していた環境は,
でした.
対処方法
pytorchを再インストールしましたが,改善しなかったので,libomp.dylib ファイル自体をどうにかしようという方針をとりました.
下記のブログを参考に,コマンドでlibomp.dylib をインストールします.
これ一行だけ実行すれば大丈夫です.
$ brew install llvm
llvm に関してはまだよく理解していません…
Wikiによると,最適化をする何かだそうです.
そして出来上がったlibomp.dylib へのリンクを作成して,作業完了です.
こちらも一行のみ実行で大丈夫です.
$ ln -s /usr/local/opt/llvm/lib/libomp.dylib /usr/local/lib/libomp.dylib
これで無事にimportができるようになりました!
参考
言語処理でよく使う前処理まとめ -tokenize, subword-

言語処理を行うときの基本として,現在は文章を単語などの何らかの単位に区切り(トークナイズ (tokenize) して),それらをベクトルに落とし込んでモデルで処理することが多いです.

今回はトークナイズ(単語を区切ること)にフォーカスして,それをでどの様に書くかを簡単にご紹介します.言語は主に python を使用します.
目次
トークナイズ
そもそもトークナイズとは,単語をトークンという単位に区切ることを指しますが,この区切り方は様々あります.よく使われるのは単語や形態素です.
さらに後ほど説明するサブワード (subword) といって,単語をさらに細かく区切った表現をトークンとして扱うことや,1文字を1トークンとして分割すること(character 分割)などもあります.
ここでは,単語・形態素分割する場合について書いていきます.
python ではライブラリが豊富に準備されているため,ほとんどの場合,ライブラリを用いて行います.今回は日本語と英語を例にトークナイズしてみます.
日本語の場合
ライブラリとしては MeCab を用います.一応,公式リンクはこちら
MeCab は条件付き確率場 (CRF: Conditional Random Fields) に基づく形態素解析エンジンです.CRF については今回解説しませんが,次に挙げる参考書にその説明が掲載されています.
インストールは pip コマンドで可能です(リンク).ビルドの方法などは,公式リンクを参照ください.
$ pip install mecab-python3
MeCab は辞書を用いてトークナイズを行いますが,pip でインストールした場合,デフォルトで mecab-ipadic になるそうです.
※変更する場合は別途設定が必要
使い方はシンプルで,インスタンスを生成して,実際にトークナイズするだけです.”-Owakati” の部分で分かち書き(トークン分割をする)ことを指定しています.
# in python code import MeCab makati = MeCab.Tagger(“-Owakati”) wakati.parse(“pythonが大好きです”).split() # output: # [‘python, ‘が’, ‘大好き’, ‘です’]
他にもオプションがあり,例えば "-Ochasen" を指定すると,
# in python code import MeCab chasen = MeCab.Tagger("-Ochasen") chasen.parse("pythonが大好きです").split() # output: # python python python 名詞-固有名詞-組織 # が ガ が 助詞-格助詞-一般 # 大好き ダイスキ 大好き 名詞-形容動詞語幹 # です デス です 助動詞 特殊・デス 基本形 # EOS
の様に,形態素解析した結果が見られます.
日本語のトークナイザとしては,他にも Juman, Janome などのトークナイザが python ライブラリとして準備されています.
※今後追記するかは未定です
英語の場合
ライブラリとしては mosestokenizer を利用します(リンク).
こちらも pip コマンドでインストール可能です.
$ pip install mosestokenizer
python で使うときは,次の様に書きます.
# in python code from mosestokenizer import * tokenizer = MosesTokenizer('en') token_list = tokenizer('I have a pen.') # output: # ['I', 'have', 'a', 'pen', '.']
因みに,mosestokenizer はヨーロッパ系の言語で幅広く利用することができ,ドイツ語やロシア語などにも適用できます.
scripts/share/nonbreaking_prefixes
に定義ファイルが存在すれば利用可能です.
定義ファイルがない場合は,次の様な Warning が出ます.
tokenizer = MosesTokenizer('ja') # output: # WARNING: No known abbreviations for language ‘ja’, attempting fall-back to English version..
shell script から利用するときは次の様に書きます.
$ cat {text_file} | moses-tokenizer en > {output_file}
英語 (en) の箇所をその他の言語に書き換えれば,ドイツ語 (de) やロシア語 (ru) などでも使用可能です.
サブワード (Subword)
近年の言語処理においては,トークナイズを行う際に,単語よりさらに小さい単位に分割することで,未知語を減らしたり,vocabulary を節約したりすることで,モデルの性能を底上げすることが多いです.
今回は有名な BPE, SentencePiece の2つの利用方法について書いていきます.
BPE (Bite Pair Encoding)
BPE の基本的な考え方は単語をさらに細かく分割していくとき,頻出する文字列の組み合わせからその分割方法を学習するというものです.
元論文はこちら

BPEの学習をする時,始めは1文字単位から出発し,上の例にみれられる様に,頻出する文字同士を結合させていきます.
上記の例の場合,"r" が文末 ("") にきていることが多いため,"r" + "" を学習し,次に "l" + "o" という結合を学習します.
これを指定した operation 数だけ繰り返します.
これが BPE の基本的なアルゴリズムです.
十分なデータで学習すると,英語でいうところの "ing", "er", "ly" など,見たことのある表現がうまく分割されるはずです.
ライブラリとしては,subword-nmt が有名です(論文の著者の GitHub です).
こちらも pip でインストールすることが可能です.
$ pip install subword-nmt
使い方としては,単語ごとにトークナイズしたのち,BPE を適用します.
※コマンドラインから使用します.
# トークナイズ $ cat {text_file} | moses-tokenizer en > {tok_file} # 学習して $ subword-nmt learn-bpe -s {num_operations} < {tok_file} > {codes_file} # 適用する $ subword-nmt apply-bpe -c {codes_file} < {applied_file} > {out_file} # vocab ファイルを作成する時 $ subword-nmt get-vocab --input {out_file} --output {vocab_file} # BPE から,通常の文字列にもどす時 $ cat {encoded_file} | sed -r 's/(@@ )|(@@ ?$)//g' > {detok_file}
{num_operations} の数,繰り返しサブワードの分割を学習していきますが,これは正確に vocabulary の数と一致しません.最終的にこのアルゴリズムを適用して得られたトークンの集合を vocaburary として扱うことになります.ご注意ください.
BPE に限った話ではありませんが,言語処理を行う際は train データを用いてサブワード (Subword) を学習し,validation, test のファイルにも適用することが通例です.
このライブラリのより詳しい使い方などは,先ほど紹介した著者 GitHub をご参照ください.
SentencePiece
先ほど紹介した BPE のアルゴリズムは,一度単語に分割してから適用する必要がありました.これ自体も手間になります.そして日本語や中国語など,スペース区切りがない言語,もっと言うとどこまでが1単語かを決めることが難しい様な言語では,単語分割の正確さにも多少の疑問が残ります.
この問題を解決するために,SentencePiece は生み出されたそうです.
詳しくは,元論文・著者の Qiita を参照ください.
基本的なアイデアは,スペースも文字として扱うことで,全て言語におい て,文を文字列とみなすという考え方です.これにより単語分割することなく,BPEや言語モデルに基づく教師なし分割を学習することを可能にしました.

こちらも,python のライブラリとして準備されています.(GitHubリンク)
インストールは,こちらも pip で可能です.
$ pip install sentencepiece
python での使用方法は次のとおりです.
# in python code import sentencepiece as spm # インポート spm.SentencePieceTrainer.Train(“--input=data --model_prefix=sp_model \ --vocab_size=16000 --character_coverage=1.0) # training sp = spm.SentencePieceProcessor() # インスタンス準備 sp.Load(sp_model) # train したモデルをロード sp_list = sp.EncodeAsPieces(item) # 学習結果を適用 decoded_text = sp.DecodePieces(sp_list) # デコード
コマンドラインで書くと,次の様になります.
$ spm_train --input={input} --model_prefix={model_name} --vocab_size=16000 --character_coverage=1.0 $ spm_encode --model={model_file} --output_format=piece < {input_file} > {output_file} $ spm_decode --model={model_file} --input_format=piece < {input_file} > {output_file}
character_coverage は,日本語などの vocabulary が多い言語で 0.9995 が良いと,先ほどのGitHub で紹介されています.
参考
URL
- MeCab 公式
- MeCab pip インストール方法について
- MeCab辞書 mecab-ipadic
- Moses pip インストール方法について
- BPE (subword-nmt) GitHub リンク
- SentencePiece に関する Qiita 解説記事
- SentencePiece GitHub リンク
図書
元論文
2020/9/6 時点参照
DeepLearning関連の学習に使用した参考書まとめ ~数学編~

私がDeepLearning関連の学習に使用した,参考書類をご紹介します.
現在も学習中なので,読んだものから追記していくつもりです.
今回は取り分け「数学」に焦点を絞ってご紹介しようと思います.
目次
全般
涌井良幸・涌井貞美『ディープラーニングがわかる数学入門』技術評論社

<感想>
最初は歯が立たなかったので,下記の参考書に取り組んだ後に取り組みました.
タイトルの通り,DeepLearningに必要な知識が身につきます.良書です.
この本の特徴的なところが,Excelを使用してDeepLearningのアルゴリズムを実際に動かしてみることができること.しかも中でどのような計算が行われているかと言うことが,このExcelを見れば一目瞭然.
必要な知識を概観したい人や技術者向けの内容になっています.
線形代数
石井 俊全『まずはこの一冊から 意味がわかる線形代数』ベレ出版

<感想>
文系大学出身者でもとっつきやすい印象.
筆者も文系出身者にも伝わるように,意識して記述している感じがあります.私は「線形代数」という言葉の意味がわからなかったのですが,そこからきちんと学べます.
読了後に,「線形代数」ってこんな感じなのか,というイメージがつかめる本です.
演習問題などはほとんどないので,実際に手を動かして覚えるのであれば,他の本も手に取ってみてください.
寺 平治『超入門 線形代数』講談社

<感想>
やはり問題演習は欠かせません.しかし,いきなり問題演習用の本を買うと,手も足も出ない……
そんな人向けの本です.簡単な演習問題が多く掲載されているので,文系出身者が手を動かすには最適かと思います.
現在絶版なのでしょうか?ネットのどこを探しても,新品の出品が見つかりませんでした.中古はネットに出回っているので,購入の際はお気をつけください.
新品を発見された方は教えてください!
石井 俊全『1冊でマスター 大学の線形代数』技術評論社

<感想>
ここからは理系の人も手応えを感じられる内容かと思います.実際に大学の単位を取る人向けに書かれている本です.なので中級者向けといったところでしょうか.
これ一冊をきちんとこなせば,DeepLearningで使用するおおよその線形代数は理解できるかと思います(勿論,DeepLearningを勉強していけばいくほど,分からないことも出てくるものですが…)
繰り返し問題を解き,実力を手にすることができる本です.
内容もしっかり充実しています!因みに私は著者の石井さんの数学解説が好みで,これからも石井さんの本が多めに出てきます.
微分積分
永野 裕之『ふたたびの微分・積分』すばる舎

<感想>
高校時代の数学を忘れてしまった方用ですが,私もこれを手に取らないと手がつけられませんでした.三角関数や指数対数関数の初歩もきちんと紹介されていて,図なども非常に見やすかったです.
今では,使う頻度がかなり減ってきてしまいましたが,もう一度数学をやり直したい方には是非手に取っていただきたい良書です.
小寺 平治『超入門 微分積分』講談社

<感想>
線形代数で紹介していた本の姉妹本です.微分積分もこの本で演習問題をとき,徐々に慣れていきます.正直微分積分の方が線形代数に比べて覚える内容が多く,挫折も多いと思います.
この本であればおそらく挫折はしないはずです.文字通り,「超入門」です.
こちらの本も現在絶版なのでしょうか?ネットのどこを探しても,新品の出品が見つかりませんでした.中古はネットに出回っているので,購入の際はお気をつけください.
新品を発見された方は教えてください!
石井 俊全『1冊でマスター 大学の微分積分』技術評論社

<感想>
線形代数の本と同じような内容になりますが,理系の人も手応えを感じられる内容かと思います.実際に大学の単位を取る人向けに書かれている本です.なので中級者向けといったところでしょうか.
今でもたまに忘れた時に使っています.
DeepLearning関連で使用する微分積分のほとんどはカバーできていると思います.私個人は大学院入試の時に大変お世話になりました.
この本も石井さん(私がお勧めする著者の方)が書かれた本です.
石村 園子『やさしく学べる微分方程式』共立出版

<感想>
使用する人は少し限られてきますが,微分方程式に関する本です.これを学ばなくてはDeepLearningが使えないことはないですが,どちらかと言うと,実社会の問題を解くために必要です.
データサイエンスをされている方(目指されている方)なら,これは必要な知識ではないでしょうか.その微分方程式の入門書だと思っていただければ大丈夫です.
今までの微分積分と毛色が違うため,とっつきにくさを感じる人にはこの本がお勧めです.
統計
石井俊全『まずはこの一冊から 意味がわかる統計学』ベレ出版

<感想>
DeepLearningのみならず,機械学習は統計に基づいています.
パターン認識(画像認識などに使われる手法)が有名ですね.
現在はプログラミング言語のライブラリ増加により,統計学を勉強していなくても実装することができるようになっています.しかし,実際の問題を解く場合において,どの手法が一番有効かを考えたり,そもそものアルゴリズムを考える上で,統計学は切って切り離せないほど重要です.
文系出身者は覚えることが多すぎると思いますが,この本は文系の私でも最初に取り組むことができました.是非一度手に取ってみてください.
一石賢『まずはこの一冊から 意味がわかるベイズ統計学』ベレ出版

<感想>
統計学といえば,ベイズの名を聞かないことは無いと思います.そのくらい重要なベイズの定理をわかりやすく紹介してくれます.
例がふんだんに取り入れられているため,数式で意味がわからなかったものを理解することができました.おそらく慣れるまでは,時間がかかり,私も何度か読み返しています.
ベイズの定理は派生系が豊富にあるため,全ての内容はわかりませんが,ベイズの定理を知らない人が理解することができる,と言う意味で良書と言えるでしょう.
微分 高校数学のおさらい
微分積分で必要な知識はいくらかありますが,先ずは高校数学のおさらいから始めたいと思います.これらの基本的な知識は現在の人工知能に使われているアルゴリズム理解にとって必要不可欠な存在です.中で何が行われているかを知りたい人は,ゆっくり学んでいきましょう.
目次
微分
微分と聞いて,接線の事を思い浮かべる人が多いと思います.これは微分係数が平均変化率の極限で求まることに起因するものです.
平均変化率とは…
「 が変化した時に
がどれほど変化するか」
ということです.
が
から
に変化したとします.
とすると,平均変化率は次のように表せます.
図で理解すると,AとBを結んだ線の傾きということになります.

この状態で,極限まで を
に近づけた時,微分係数が求まります.微分係数は次の式で与えられます.
※どちらも同じ意味です.
図で理解すると,次のようになります.

⬇️

接線になりました!! まとめると,
となります!
n次関数の微分
さて,一般的な表記が求まったところで,実際の関数 に当てはめて考えてみましょう.
(
は定数) の時,上記の式の分子は必ず0になります.この事を利用して,次の式が導けます.
では が
次関数の場合について解いていきましょう.
のとき
二項定理より,
となる事を利用して,
よって,
有名な公式が求まりました!
合成関数の微分
少しだけ発展的な内容になります.次のような関数を考えます.
つまり, の
部分が他の関数
で表現できるような関数(
と
の合成関数)の微分を考えます.
まとめると
となります.意外と便利な公式です.違う表記を取ると,次のようにも表現できます.
の部分が
に相当する部分です.実際に計算してみましょう.
のとき,
とすると
となります.便利さがわかっていただけたでしょうか.
積と商の微分
まず積の微分を考えます.具体的には次のような関数の微分を考えます.
微分すると,
とおくと,
となります. について解くと,
まとめると
これにて完了です.お疲れ様でした.
思い出すのに苦労しますが,導出できるようになれば確認できます.覚えておきましょう!